操作系统期末复习一文贯通
此课程维持了南软诸多专业课的一贯的水准。理论部分底蕴悠久,一脉相承,与南软同寿
– 南软佛脚玩乐指南
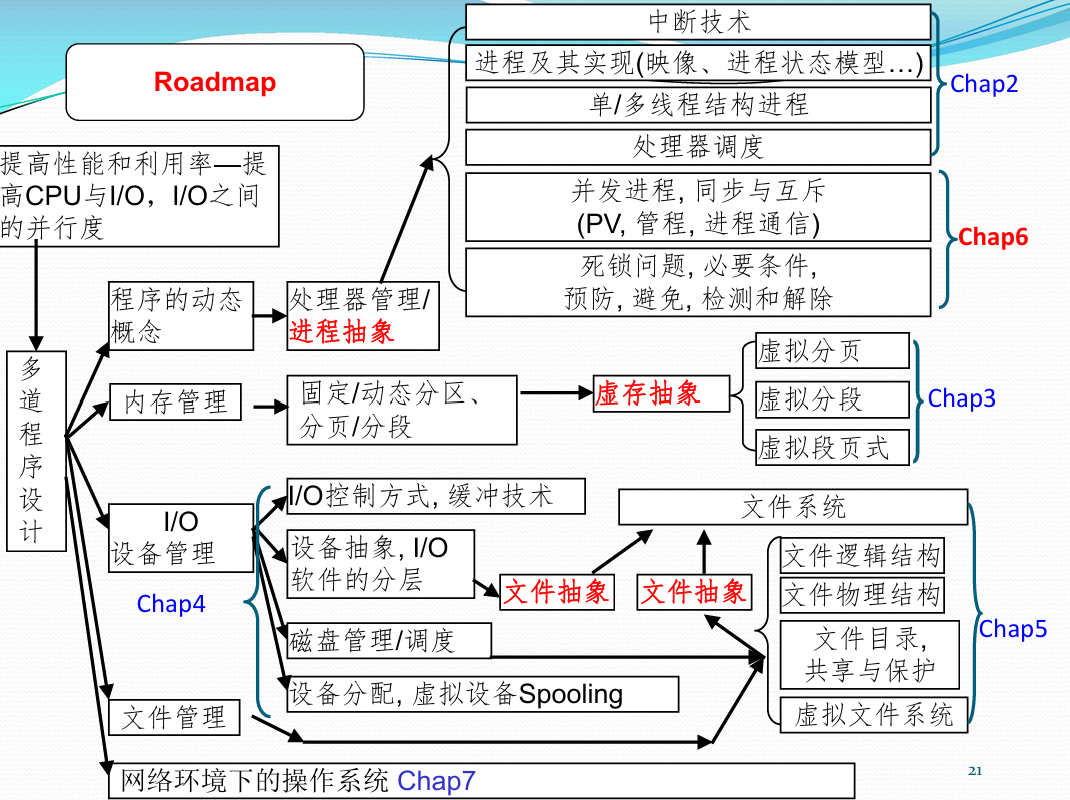
课程学习路线总览
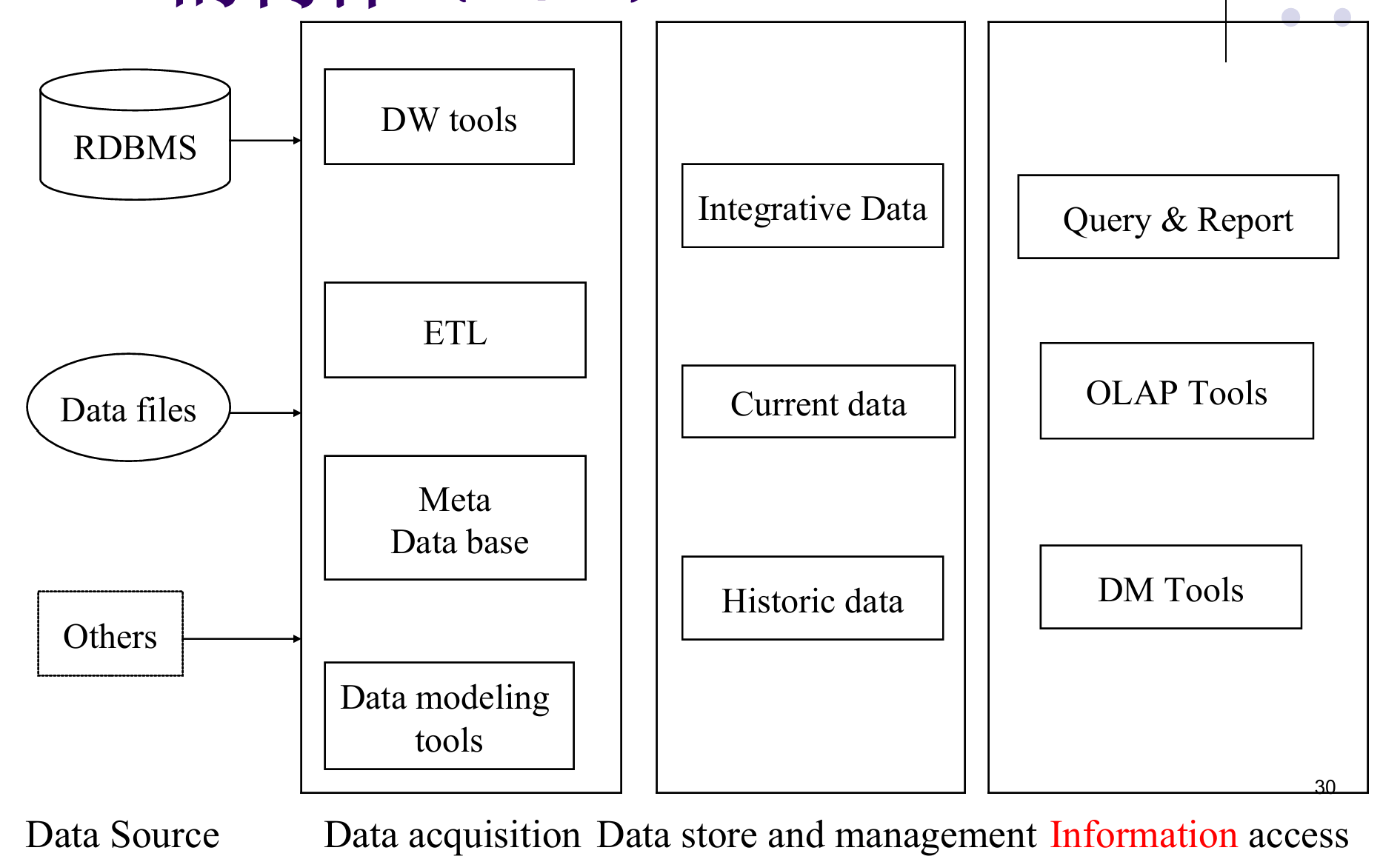
操作系统是计算机系统的核心系统软件,负责管理硬件资源、控制程序运行、为用户提供接口。整个课程围绕”资源管理“和”程序控制“两条主线展开,涵盖进程管理、内存管理、文件管理、设备管理四大资源管理功能,以及并发程序设计这一核心控制问题。
此课程维持了南软诸多专业课的一贯的水准。理论部分底蕴悠久,一脉相承,与南软同寿
– 南软佛脚玩乐指南
操作系统是计算机系统的核心系统软件,负责管理硬件资源、控制程序运行、为用户提供接口。整个课程围绕”资源管理“和”程序控制“两条主线展开,涵盖进程管理、内存管理、文件管理、设备管理四大资源管理功能,以及并发程序设计这一核心控制问题。
井壁磴道如肋,苔从石罅渗出,碧色浸人,湿可鉴影。趾扣阶棱,觉石面经前趾磨啮,已成弧凹。下及井底,鼎高过丈,锈叠如鳞,底锈已玄。鼎中沙沸,不闻水响,惟沙砾相戞,作燥白声,若万蚁啮骨。热气袭面,初觉灼,旋即枯。
桥白玉,泥地雨渥,桥面滑腻若脂,无纤尘。翁立桥首,掷钱于空,钱坠泥中,半没。俯身欲拾,翁叱之,声沉若自膈出。敛手归舍,舍中已有携其钱者,锈色新伪,心知其异。欲掷窗外,启牖,桥首设丧,翁尸在焉,吏卒翻泥索钱,遍搜行客。急纳钱于袖,下楼。阶无尽,每层皆达一皓白广厅,厅心立短杆,悬黑旂一,升之极缓,若溺者浮水。四围忽集多人,寂然同趋,环杆而跑,禁步惟驰。
入店市物,人潮拥塞,踵接肩摩,几至足不履地。掌中攥铜钱数枚,及付,钱化为赤齿轮,雕镂精绝。贾人色变,叱曰:”伪币!”四顾人迹顿空,堂宇豁然。怖而反奔,长廊幽邃,渐窄渐软,终至匍匐乃进。尽处一室逼仄,中设桌案,案下有柜。启之,柜底列赤钱如阵,粘固不可取,若本就在彼。
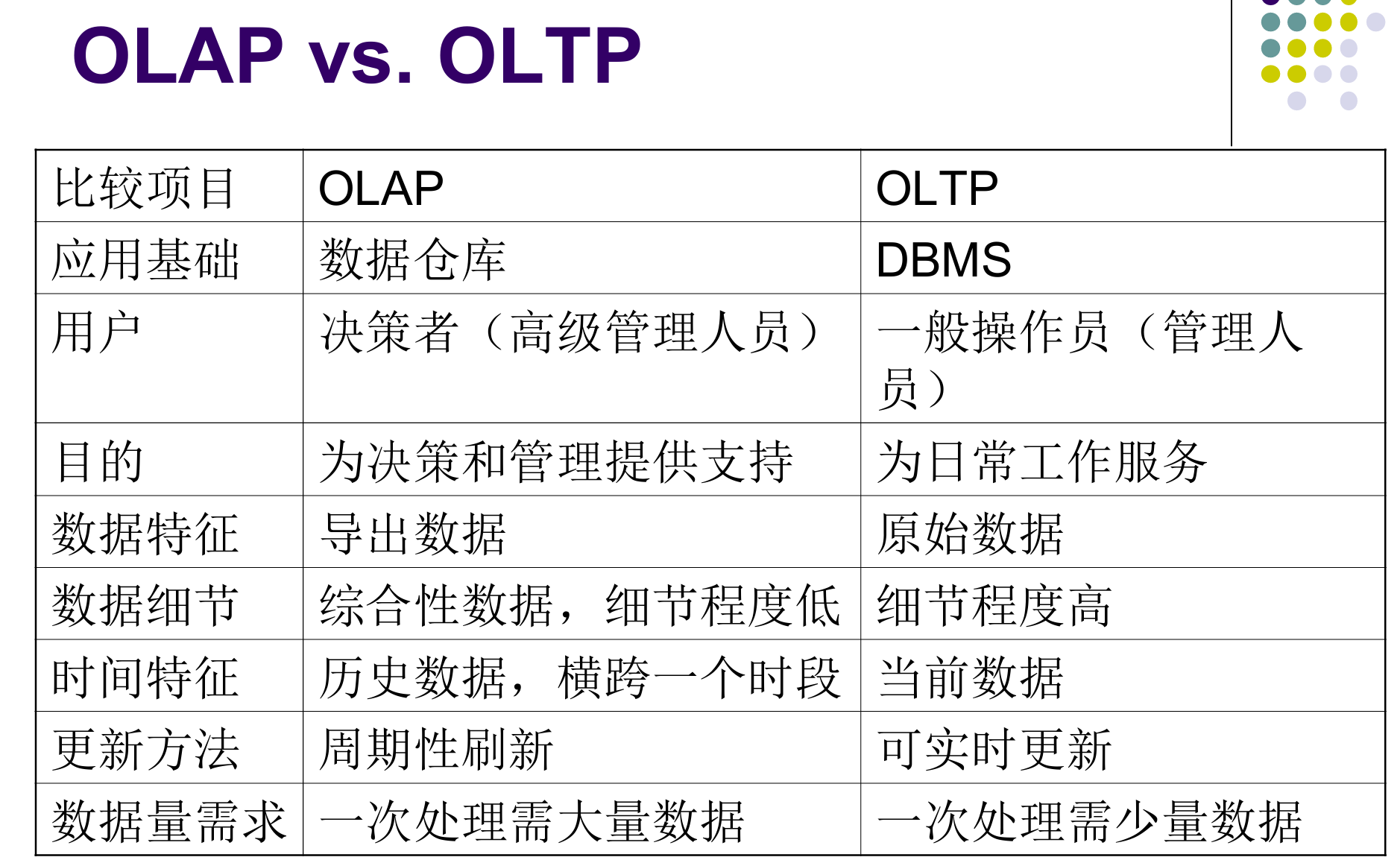
| 维度 | 操作型数据库 (OLTP) | 数据仓库 (DW) |
|---|---|---|
| 处理类型 | 面向应用 (日常事务) | 面向分析 (决策支持) |
| 需求 | 确定、明确 | 不确定、不断变化 |
| 设计目标 | 事务处理性能 (高并发) | 全局一致的数据环境 (历史、集成) |
| 输入 | 事务相关数据 | 多种多样 (来自多个源系统) |
| 设计方法 | SDLC (系统生命周期) | CLDS (需求在后期明确) |
如下
本文是题目导向的,立足于期末考试可能会出现的题目,并且对于提到的相关概念做了一个简单整理
程序的运行时内存通常划分为三个主要区域,分别存放不同生命周期的数据:
main 和 sub 函数的代码)。由于大小在编译时已知,属于静态区域。BP (栈底指针) 和 SP (栈顶指针) 管理。malloc/new 申请的对象),由程序员手动释放或由垃圾回收器管理。